






We present jax-cosmo, a library for automatically differentiable cosmological theory calculations.
jax-cosmo uses the JAX library, which has created a new coding ecosystem, especially in probabilistic
programming. As well as batch acceleration, just-in-time compilation, and automatic optimization
of code for different hardware modalities (CPU, GPU, TPU), JAX exposes an automatic differenti-
ation (autodiff) mechanism. Thanks to autodiff, jax-cosmo gives access to the derivatives of cos-
mological likelihoods with respect to any of their parameters, and thus enables a range of powerful
Bayesian inference algorithms, otherwise impractical in cosmology, such as Hamiltonian Monte Carlo
and Variational Inference. In its initial release, jax-cosmo implements background evolution, linear
and non-linear power spectra (using halofit or the Eisenstein and Hu transfer function), as well as
angular power spectra (C`) with the Limber approximation for galaxy and weak lensing probes, all
differentiable with respect to the cosmological parameters and their other inputs. We illustrate how
automatic differentiation can be a game-changer for common tasks involving Fisher matrix computa-
tions, or full posterior inference with gradient-based techniques (e.g. Hamiltonian Monte Carlo). In
particular, we show how Fisher matrices are now fast, exact, no longer require any fine tuning, and
are themselves differentiable with respect to parameters of the likelihood, enabling complex survey
optimization by simple gradient descent. Finally, using a Dark Energy Survey Year 1 3x2pt analysis
as a benchmark, we demonstrate how jax-cosmo can be combined with Probabilistic Programming
Languages such as NumPyro to perform posterior inference with state-of-the-art algorithms including
a No U-Turn Sampler (NUTS), Automatic Differentiation Variational Inference (ADVI), and Neural
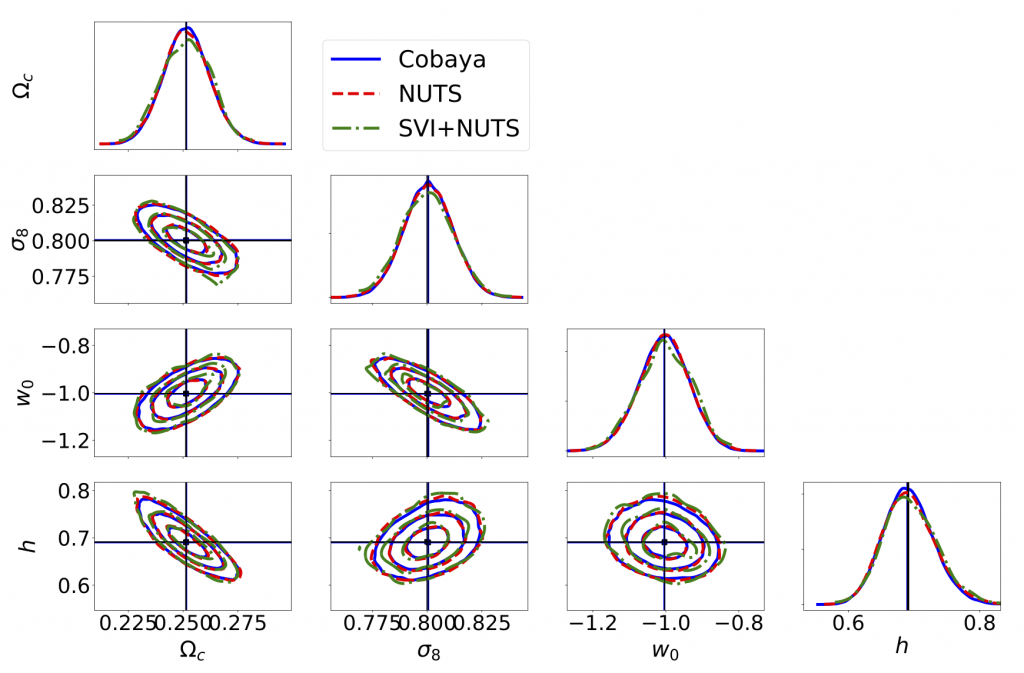
Transport HMC (NeuTra). We show that thee effective sample size per node (1 GPU or 32 CPUs) per
hour of wall time is about 5 times better for a JAX NUTS sampler compared to the well optimized
Cobaya Metropolis-Hasting sampler. We further demonstrate that Normalizing Flows using Neural
Transport are a promising methodology for model validation in the early stages of analysis.